
The Knowledge Vault Was Recently Announced
This morning, at the 20th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), Google may announce that they are trying a new approach with a knowledge base, applying a mix of technologies to automate a lot of the collection of information that helps in:
- Fueling efforts at Google to present more and better knowledge panel results
- Helping Google recognize entities (specific people, place and things) within queries
- Making predictive algorithms for personal assistants such as Google Now & Siri & Cortana smarter and more assistive
- Bringing Us New Applications and Undiscovered Uses
The announcement carries with it a lot of new information about approaches Google follows to deliver more information to people faster, in a more complete form. Before you delve too quickly into this topic, reading the following paper (PDF) from Google is highly recommended:
Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion.
The Knowledge Vault Was An Effort to Get Knowledge Base Information to Scale Better
At the Semantic Web Conference, a common theme in presentations from search engineers such as Google Fellow Ramanathan Guha was the importance of getting knowledge base information to scale better and help applications from rich snippets to knowledge panels, to mobile apps, and others. These many different kinds of applications need to be able to use such information, and the more information that is available, the more effective they will be.
Related Content:
For example, there have been medical studies conducted by organizations for the US Government where the conclusions have been online, but the data itself from the studies haven’t been shared. It’s a shame that knowledge isn’t shared in a way that could help others.
The new Knowledge Vault doesn’t have as much information as Google’s Freebase knowledge base. Freebase has 637M (non-redundant) facts, and the Knowledge Vault has only 302M “confident” facts. Of that, only 223M are in Freebase. There are many missing values for facts in Freebase entities, with 71% of people in Freebase having no known place of birth, and 75% having no known nationality. But the increase in the “confidence” of facts included in the Knowledge Vault is significant.
Sometimes some problems make creating a Freebase entry difficult.
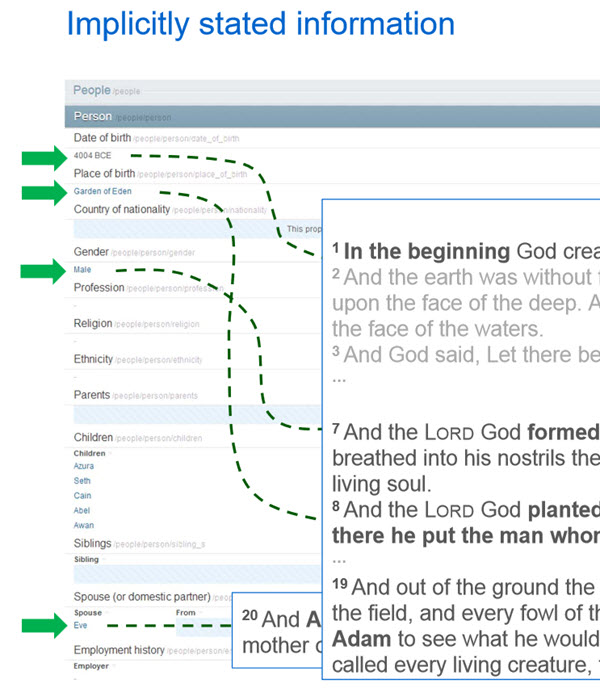
Google’s been working upon this automated approach to building the Knowledge Vault with greater confidence in the facts it includes, using methods such as:
- Extracting information from Google’s Knowledge Graph (Not just a reuse, but a review of the information before reuse.)
- Using an Open Information Extraction approach such as that created by Wavii, on the Web and from sources like news streams
- A quiz crowdsourcing approach to finding knowledgeable people who might answer questions that add to the Knowledge Vault, titled Quizz: Targeted Crowdsourcing with a Billion (Potential) Users.
A detailed presentation for KDD titled Constructing and Mining Web-scale Knowledge Graphs is worth downloading and studying if you want more details.
With this faster-automated approach to building and representing knowledge by Google with the Knowledge Vault, we’re pretty excited by how much more information this can provide to searchers, and how many more opportunities it can bring to site owners.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: